Introduction to our series on the extended Berkeley Packet Filter (eBPF).
Anyone following Linux kernel advancements has undoubtedly heard of the term eBPF. The extended Berkeley Packet Filter, or eBPF, is a Linux subsystem that can run arbitrary bytecode in a virtualized environment inside the Linux kernel without the need to change kernel source code or load kernel modules. In the last couple of years, the eBPF technology has spearheaded new tools in networking, systems performance engineering, application tracing and security.
The original Berkeley Packet Filter (BPF), referred to as classic BPF (cBPF), captured and filtered network packets matching specific rules. BPF provided an in-kernel, virtual machine-like construct that allowed executing bytecode at various hook points. Linux kernel version 3.18 release in 2014 included the first eBPF implementation that expanded on the original BPF architecture by providing a suite of tools for writing generic programs that are run efficiently and safely in the kernel space.
eBPF program
eBPF programs are triggered by events and are run when the kernel or an application passes a certain hook point.
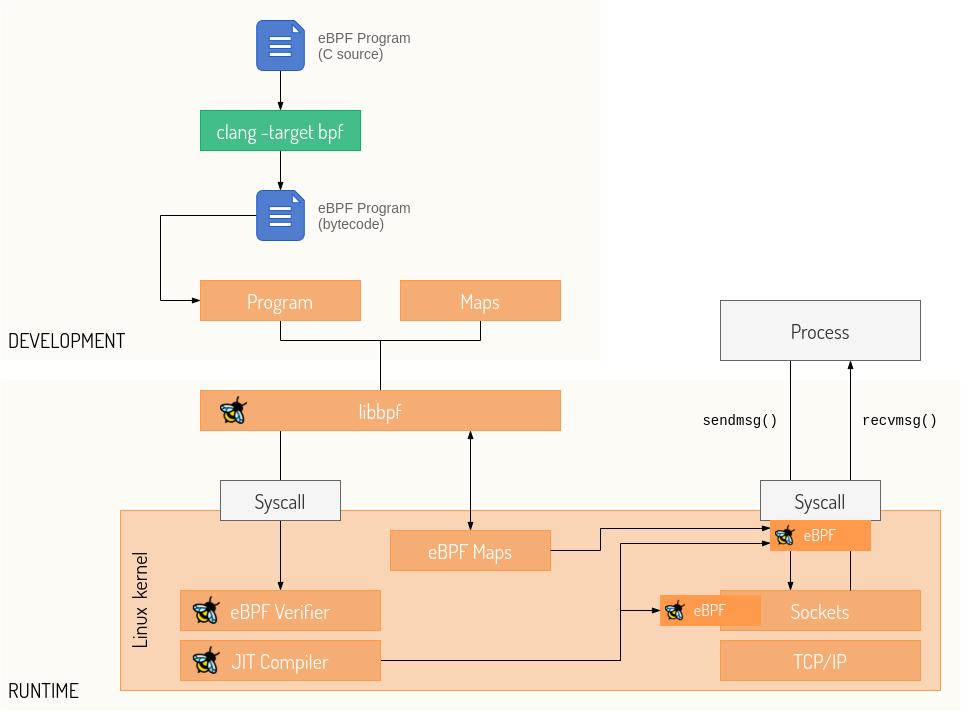
Source: ebpf.io
{kind=link}
The growing diversity of these hook points is one of the reasons why new use cases for eBPF continue to emerge. Some examples of these hook points include:
• System calls - Execute eBPF programs when userspace functions transfer execution to the kernel
• Network events - Attach eBPF programs to sockets, the traffic control subsystem and tunnels. Additionally, eBPF programs can attach to the earliest networking driver stage through a fast data path subsystem called the eXpress DataPath (XDP).
• Tracepoints, kprobes and uprobes - Attach eBPF programs to tracepoints, kernel probes (kprobes) and userspace probes (uprobes) to gain visibility into system performance and application behavior. Moreover, a special type of probe known as a User Statically-Defined Tracing (USDT) probe provides a low-overhead way of debugging applications running in production.
Every eBPF program loads into the kernel in the form of bytecode. Rather than directly write bytecode, developers use compiler suites such as LLVM to compile pseudo-C code into eBPF bytecode. The pseudo-C code has various restrictions to simplify static analysis done by the verifier during program load. Some examples of these restrictions include the ability to only use loops with a number of iterations known at compile time, a limited stack size and the inability to use functions other than bpf-helper functions and static inline functions. A more in-depth list of restrictions is available in resources such as the Cilium BPF and XDP Reference Guide.
Once the targeted hook is triggered, the eBPF program is loaded into the Linux kernel via the bpf() system call. Before the program attaches to the hook, it first has to pass a certain set of requirements in a VM-like environment to ensure it is safe to run. Once the program is verified, the Just-in-time (JIT) Compiler translates the program to native machine instructions, which means that eBPF execution speed gets as close as possible to native execution.
Several development toolchains ease the development and management of eBPF programs. The most notable examples are the BCC toolkit for creating efficient kernel tracing/manipulation programs and the libbpf C library that provides an API for opening and loading BPF bytecode contained in Executable and Linkable Format (ELF) files.
About This Series
Newcomers to eBPF have a large variety of educational materials at their disposal (websites such as ebpf.io, BPF and XDP Reference Guide and Awesome eBPF are excellent sources for both novice and advanced topics).
This post series takes a closer look at eBPF, its diverse use cases and the applicability of eBPF to embedded systems. In the series, we will provide a brief introduction to eBPF, walk you through writing a simple eBPF application, examine how to use our Open Source builder (Replica.one) to build the application for the Raspberry Pi device, and much more in between. We hope you will join us for the first installment in the series.
Sartura eBPF Engineering Services
Developers around the world continue to scratch the surface of how to use eBPF. While the amount of resources on eBPF is increasing, getting started with this low-level technology can be overwhelming at first.
Sartura offers a range of eBPF development, integration and education services tailored for companies interested in eBPF:
• eBPF application development: Delivering custom eBPF applications in the field of observability, tracing, security and networking to enable you an unprecedented level of insight into your operations and improve performance
• eBPF training and support: Professional training sessions on eBPF. Our tailored eBPF sessions jumpstart your team and accelerate eBPF adoption.
Want to find out more about our line of eBPF services? Contact us at info@sartura.hr.